![]()
![]()
![]()
![]()
1. Einführung
und Aufgabenstellung
Das World Wide Web (WWW) stellt heute in der Gemeinde der Computerbenutzer eines der bedeutendensten Mittel zur Bereitstellung von und zum Zugriff auf Informationen dar. Aufgrund seines plattformunabhängigen, graphischen Benutzeroberflächenkonzeptes und der einfachen Bedienbarkeit, die von den Zugriffsprogrammen - genannt Browser - wie NETSCAPE NAVIGATOR realisiert werden, können selbst Computerlaien ohne große Kenntnisse vom physikalischen Ort der Informationsspeicherung, und von den internen Vorgängen, die durch das Netzprotokoll HTTP gesteuert werden, Informationen abrufen. Dem Benutzer bleibt es erspart, eine große Anzahl von Befehlen oder eine Syntax zur Steuerung des Browsers zu erlernen.
Die einzige Einschränkung bei der einfachen Bedienung liegt in der Darstellung von Adressen im WWW, nämlich in der Form der Uniform Resource Locators (URL). Ohne Fachkenntnisse erscheint eine Adresse der Form "http://userver.informatik.uni-wuerzburg.de/intro.html" als eine unverständliche Ansammlung von Zeichen, aber in den meisten Fällen benötigt er auch keine Kenntnis über deren Bedeutung, da die Adressen nicht direkt eingegeben werden müssen.
Nur die Startadresse, die sogenannte "Homepage ", muß vom Systemadministrator voreingestellt werden.
Der Einfluß des WWW ist in den letzten zwei Jahren rasant gewachsen und ein Ende des Wachstums ist nicht abzusehen, da im Moment ein immenses öffentliches Interesse auf diesem Medium liegt und in gewissen (kommerziellen) Bereichen es zur Zeit eine Art Statussymbol darstellt, im WWW vertreten zu sein. Es werden zur Zeit sogar von verschiedenen Firmen, darunter SUN, ORACLE und APPLE, sogenannte "Internet-Machines" entwickelt: Rechner, die ohne Festplatte und Monitor auskommen sollen und nur für die Benutzung des Internets konzipiert sind. Als Bildschirm soll für diese Terminals ein Fernseher ausreichen.
Die meisten der Informationen im WWW befinden sich in einem Dateisystem auf einem "Server"-Rechner, entweder als Text in der Darstellungssprache HTML, die mit dem Browser dargestellt werden, oder als Binärdateien, die der Benutzer als ganzes zu seinen eigenem Rechner übertragen kann.
HTML stellt eine einfache Möglichkeit dar, Informationen im WWW darzustellen, wobei gute Gliederungsmöglichkeiten über Verweise auf andere Seiten existieren. Die Syntax der Sprache ist recht einfach zu erlernen und es existieren inzwischen eine Reihe von Editoren zum Entwurf von HTML-Seiten. HTML stellt zur Zeit keine fest definierte Sprache dar, sondern sie wird kontinuierlich weiterentwickelt und erweitert, so daß mehrere Standards (HTML 2 und HTML 3) und Quasi-Standards von Herstellern (die vor allem von NETSCAPE vorangetrieben werden) nebeneinander existieren.
Die Binärdateien, die der Benutzer auf seinen eigenen Rechner - genannt Client - laden kann, können von ausführbaren Programmen über komplette Datenbanken oder Archiven alles enthalten, was Dateien auch auf einem lokalen Rechner darstellen können. Im Prinzip also nur eine Folge von Binärdaten, die erst mit einer Interpretation als Bilder, Datensätze oder Programme Sinn ergeben. Die Auswertung von bestimmten Arten von Binärdaten (z.B. Filme oder Archivdateien) kann am Client erfolgen, indem externe Viewer aufgerufen werden (die z.B. den Film abspielen) oder intern vom Browser durch sogenannte "Plug-Ins" dargestellt werden.
Man kann also die Daten komplett an den Client schicken, aber nicht dem Benutzer spezielle Teile dieser Daten, die der Benutzer eigentlich benötigt, zur Verfügung stellen, da die Möglichkeit, auf diese Daten zuzugreifen, fehlt. Dieses Manko wurde früh erkannt, und es wurden eine Vielzahl von Erweiterungen entwickelt, die dies beheben. Diese Erweiterungen beruhen auf dem Ansatz, die Daten am Server auszuwerten und das Ergebnis der Auswertung dem Client als HTML-Seite zu übergeben.
Das Problem liegt darin, daß die in den HTML-Dateien
gespeicherten Informationen statisch sind. Gesucht wird aber eine
Methode, bestimmte, durch den Benutzer spezifierte Daten zu übertragen
und darzustellen. Die vom Benutzer angeforderten Daten sind im
allgemeinen in einem Format gespeichert, das eine direkte Darstellung
nicht gestattet. Daher benötigt man die Möglichkeit
der dynamischen HTML-Seitenerzeugung, so daß man die Anfragen
der Benutzer zuerst bearbeiten kann, und das Ergebnis der Anfrage
als besondere Seite mit ansprechender optischen Gestaltung darbietet.
In dieser Studienarbeit ist ein möglicher Ansatz zur dynamischen
Generierung von HTML-Seiten entwickelt worden.
Das in dieser Studienarbeit entwickelte System basiert
auf dem Projektpraktikum "Intelligente Informationssysteme"
auf, das im WS 95 / 96 am Lehrstuhl VI für Informatik der
Universität Würzburg stattfand.
In Kapitel 2 Vorstellung alternativer Lösungen
werden einige der Ansätze vorgestellt, die dieses Problem
behandeln. Ziel und Aufgabenstellung dieser Studienarbeit ist
es, eine Möglichkeit des Zugriff auf Informationen, die vom
Benutzer speziell angefragt wurden, zu entwickeln. Dabei sind
folgende Nebenbedingungen gegeben:
Im speziellen wurden folgende Programme an den Server
angebunden:
Die Anbindungen an diese Programme bieten folgendes
Grundmuster an Möglichkeiten an:
Die verwendeten Datenbanken und Dokumente werden im Kapitel 3.5 Implementierte Anbindungen vorgestellt. Die angebundenen Daten sollten im Sinne von Beispielen für das implementierte System verstanden werden.
Die Konfiguration der Anbindungen, welche auf dem
Server zur Verfügung stehen, soll zur Laufzeit des Servers
und über die vom Server angebotenen Dienste ermöglicht
werden. Dadurch ist es für den Verwalter des Systems jederzeit
möglich, von seinem eigenen Rechner mit Hilfe eines Browsers
das System zu steuern.
Ein weiterer Schwerpunkt dieser Studienarbeit liegt in der automatischen Erstellung und Verwaltung der LISP-Programmierumgebungen des Lehrstuhls. Um eine ablauffähige Version der Expertensystem-Shell D3 zu erstellen, muß ein neues Speicherabbild der Umgebung erstellt werden. Um diesen sogenannten "Dump" zu erstellen, muß in eine vorhandene Grundbibliothek eine große Anzahl von Erweiterungen geladen werden, so daß das Erstellen eines Dumps einige Zeit benötigt. Wenn der Dump erstellt worden ist, muß er auf die Rechner der mit dieser Umgebung arbeitenden Entwickler verteilt werden. Diese Entwickler müssen davon informiert werden, daß ein neuer Dump existiert und welche Unterschiede zur letzten Version existieren. Das Kopieren des Dumps, der eine Größe von einigen Megabyte (zwischen 3 und 8 MB) besitzt, auf mehrere Rechner, stellt in einem lokalen Netz eine große Netzbelastung dar, die man dadurch vermeiden kann, daß diese Aktionen zeitversetzt, z.B. nachts, ausgeführt werden.
Die verschiedenen Dumps werden auf einer Festplatte zentral archiviert. Wenn ein neuer Dump erstellt worden ist, muß er diesem Archiv hinzugefügt werden.
Um dieses zu realisieren, ist folgendes System in
dieser Studienarbeit entwickelt worden:
Die Benutzeroberfläche soll ebenfalls durch
HTML zugänglich sein.
Der Teil des Dump-Systems, der die email-Anbindung
behandelt, wurde zur gleichen Zeit in der Studienarbeit von Christoph
Oechslein verwirklicht. Die beiden Studienarbeiten sind zu diesem
Thema im Zusammenhang zu betrachten. Dieser Teil bietet folgende
Möglichkeiten:
Da die obengenannten Funktionen teilweise schon vorhanden
sind, aber im Großen und Ganzen zu unkomfortabel sind, liegt
ein Schwerpunkt darauf, eine möglichst einfache und schnelle
Bedienung zu erlauben, so daß sich für die Entwickler
ein meßbare Zeitersparnis ergibt.
![]()
![]()
![]()
![]()
![]()
2. Vorstellung
alternativer Lösungen
Es existieren bereits viele Ansätze, wie man
dynamisch auf Spezifikation des Benutzers hin, Informationen im
WWW zur Verfügung stellt. Einige davon sollen an dieser Stelle
vorgestellt werden.
![]()
![]()
![]()
![]()
![]()
JAVA ist eine objektorientierte, plattformunabhängige Programmiersprache, die von SUN MICROSYSTEMS entwickelt wurde. Die Syntax von JAVA ist an die Programmiersprache C++ angelehnt und unterscheidet sich somit stark vom Konzept von HTML.
Während HTML darauf beruht, daß Dokumente
in dieser Sprache vom Browser am Bildschirm des Client angezeigt
werden, verfolgt JAVA einen anderen Ansatz. Es wird über
das Netz ausführbarer Bytecode verschickt, der auf dem lokalen
Rechner ausgeführt wird. Da dieser lokale Rechner über
eine beliebige, vom Server verschiedene Rechnerarchitektur verfügen
kann, muß ein solches Programm in einem systemunabhängigen
Format vorliegen. Aus diesem Grund wird zur Interpretation dieses
Codes ein spezieller Browser benötigt. Dieser ist z.B. das
ebenfalls von SUN entwickelte Benutzer-Frontend HOTJAVA. JAVA
besteht somit aus folgenden drei Schichten [Wol96]:
Neben Objekten und hoher Portabilität bietet JAVA preemptives Multitasking (auf Plattformen, die dieses anbieten), Robustheit gegenüber Laufzeitfehlern und eine dynamische Speicherverwaltung mit Garbage Collection.
Der zur Zeit verbreiteste Browser NETSCAPE hat ab der Version 2.0 den Sprachumfang von HTML erweitert, so daß mit diesem Browser ebenfalls JAVA-Programme, genannt "Applets", ausgeführt werden können. Dazu wurde ein neues Element ("Tag") <applet> hinzugefügt, das die Einbindung und Ausführung von JAVA-Applets ermöglicht. Damit soll die Einfachheit von HTML erhalten werden und zugleich die Mächtigkeit von JAVA voll ausgenützt werden.
JAVA stellt eine im Vergleich zu HTML bedeutend mächtigere Sprache dar, zumal der Einsatz von JAVA im Prinzip nicht auf das WWW beschränkt ist.
Gleichzeitig wurden Vorkehrungen getroffen, daß
die Programmierer von JAVA-Programmen die Mächtigkeit nicht
mißbrauchen können. Durch das Ausführen eines
Applets auf einem fremden Rechner, wobei derjenige, der dieses
Applets aufgerufen hat, keinen Einfluß und keine Einsicht
auf dessen Interna hat, lassen sich ansonsten alle Sichherheitsvorkehrungen
gegen Ausspähung von Daten und Schutz vor Viren umgehen.
Einem JAVA-Applet ist es z.B. nicht erlaubt, Datenträger
des Clients ungefragt zu benutzen.
Auf das zu behandelnde Problem der dynamischen Antwortgenerierung auf Anfragen angewandt, würde eine Verwendung von JAVA folgendes bedeuten:
Der Programmierer muß in JAVA Programme implementieren und kompilieren, die die Anfrage des Benutzers am Server auswerten, und die Ergebnisse der Anfrage an ein Applet (oder sogar als komplettes Applet) zum Client zurückschicken und dem Benutzer präsentieren.
Damit sind die größsten Nachteile mit
JAVA offensichtlich:
Um diese Probleme zu umgehen, wurde gemeinsam von SUN und NETSCAPE eine Vereinfachung von JAVA erarbeitet. Diese heißt JAVASCRIPT und stellt eine Mischung zwischen einer im Sprachumfang reduzierten Version von JAVA und dem von NETSCAPE entwickelten LIVESCRIPT dar. Ein JAVASCRIPT ist ebenfalls eine HTML-Erweiterung, in der Teile der Klassenhierarchie von JAVA verwirklicht worden sind.
Damit entfällt der Schritt der Kompilierung,
die Befehle werden direkt in das entsprechende HTML-Dokument eingefügt
und vom Browser ausgeführt. JAVASCRIPT besitzt fest definierte
Klassen, deren Methoden aufgerufen werden können. Im Gegensatz
zu JAVA ist es nicht möglich, eigene Klassen zu definieren.
Das folgende kurze Beispiel dazu ist aus [Jav95]
entnommen, und zeigt ein einfaches JAVASCRIPT, das einen Taschenrechner
simuliert:
<HEAD>
<SCRIPT LANGUAGE="JavaScript">
function compute(form) {
if (confirm("Are you sure?"))
form.result.value = eval(form.expr.value)
else
alert("Please come back again.")
}
</SCRIPT>
</HEAD>
<BODY>
<FORM>
Enter an expression:
<INPUT TYPE="text" NAME="expr" SIZE=15 >
<INPUT TYPE="button" VALUE="Calculate" ONCLI TYPE=DISCCK="compute(this.form)">
<BR>
Result:
<INPUT TYPE="text" NAME="result" SIZE=15 >
<BR>
</FORM>
</BODY>
Es ist schon aus diesem kleinen Beispiel ersichtlich,
wie hiermit dynamisch Seiten generiert werden können. Da
durch JAVASCRIPTS viele Aktionen direkt am Client ausgeführt
werden können, wird damit eine Entlastung des Internets,
das sowieso schon größere Probleme mit der Netzlast
hat , als auch des Server, verwirklicht. JAVASCRIPT befindet sich
zur Zeit noch in der Entwicklung, so daß hier die weitere
Entwicklung abgewartet werden muß. Für Details sei
auf [Beh95] und [Min96] verwiesen.
![]()
![]()
![]()
![]()
![]()
Während JAVA und JAVASCRIPT Möglichkeiten darstellen, am Client dynamisch HTML-Seiten zu erzeugen, ist das Common Gateway Interface - abgekürzt CGI - die am weitesten verbreitete Methode, Anfragen an den Server zu bearbeiten und aus den Anfragen Antworten zu generieren. CGI wird von fast allen heutigen HTTP-Servern zur Verfügung gestellt.
Die Funktionsweise der CGI ist einfach zu erklären: Auf dem Server wird ein Verzeichnisbaum festgelegt, dessen Wurzel üblicherweise die Bezeichnung "/cgi-bin/" trägt. Dadurch hat der Server eine Kontrollmöglichkeit, welche Programme überhaupt ausgeführt werden dürfen, da sonst erhebliche Sicherheitsprobleme entstehen würden. In diesen Verzeichnisbaum können sowohl HTML-Dateien als auch ausführbare Programme abgelegt werden. Auf UNIX-Systemen sind dies meist Skriptdateien, da diese ohne Neukompilierung geändert werden können, aber es kann jedes ausführbare Programm verwendet werden. Dieses läßt sich genau wie eine HTML-Datei aufrufen. Anstatt den Inhalt dieser Datei an den Client zu übertragen, führt der Server das Programm aus und verschickt die Ausgabe des Programms.
Dabei besteht die Möglichkeit, dem Server Argumente zu übergeben, der diese an die Programme weiterreicht. Dabei wird die Angabe der URL um gewisse Optionen erweitert. Im Normalfall besteht die URL aus der Angabe des Protokolls, der Identifizierung des Servers und der genauen Angabe der gewünschten Seite. In der URL "http://userver.informatik.uni-wuerzburg.de/is/Beispiel.html" wird das Protokoll HTTP verwendet, der Server hat den Namen "userver.informatik.uni-wuerzburg.de", der von einem Nameserver in eine IP (z.B. "132.187.105.160") umgesetzt wird. Die gewünschte Seite hat den Pfad "/is/Beispiel.html".
Man kann Argumente übergeben, indem man nach
der URL ein "?" und das Argument (oder mehrere, durch
"+" getrennte Argumente) an den Server schickt. In der
gleichen Weise funktioniert das Übergeben von Argumenten
durch eine HTML-Form. Die CGI-Skripten benutzen also die meist
vorhandene Standardein- und ausgabe, was die Programmierung dieser
Skripten vereinfacht, da man sich nur auf das Wesentliche, nämlich
die Auswertung der Argumente und die Generierung der Antwort beschränkt.
Zusätzlich existiert noch eine Möglichkeit, statischen
HTML-Code und CGI-Skripten zu verbinden, in dem man in einer HTML-Seite
ein CGI-Skript aufrufen kann. Auf APPLE-Systemen bieten sich als
Programme APPLESCRIPTS an.
Zur Erläuterung des Konzeptes dient folgendes
kleine Beispiel, welches die Anzahl der Zeilen auf einer HTML-Seite
zählt:
<HTML> <HEAD><TITLE>Anzahl der Zeilen in dieser Datei:</TITLE></HEAD> <BODY> Diese Datei hat <!--exec cmd="/cgi-bin/zeilen"--> Zeilen. </BODY> </HTML>
Dies ist die HTML-Seite, die aufgerufen wird. Ihr Name ist "/cgi-bin/woerter.html". Die HTML-Datei ist in diesem Beispiel ebenfalls im CGI-Verzeichnis abgelegt, sie könnte auch an einer anderen Stelle stehen.
Und dies ist das Programm "/cgi-bin/zeilen",
das von dieser Seite aufgerufen wird, in diesem Fall ein UNIX-Shellskript:
#!/bin/sh wc -l /cgi-bin/woerter.html cut -c 1-9
Das Konzept der CGI-Skripten ist durchaus mit der
in Kapitel 3.5.3 Ausführen von AppleScripts entwickelten
Lösung vergleichbar. Für weitere Informationen über
CGI verweise ich auf [W3C96] und [Ncs95].
![]()
![]()
![]()
![]()
![]()
Das Konzept der CGI ist sehr allgemein gehalten,
wodurch eine sehr mächtige und flexible Möglichkeit
geschaffen wird, Anfragen an den Server auszuwerten und Antworten
zu erzeugen. Speziell für die Anbindung von Datenbanken an
das WWW wurden einfachere Zugriffsmöglichkeiten entwickelt,
von denen in diesem und im nächsten Abschnitt zwei Varianten
vorgestellt werden sollen. Das erste Beispiel behandelt die Anbindung
des für UNIX-Umgebungen vorhandenen Datenbankprogramms mSQL,
welches für "Mini SQL"steht. Wie der Name
andeutet, bietet mSQL eine reduzierte Version der Datenbanksprache
SQL. Die Erweiterung "W3-mSQL" ist ein Beispiel
für die geschickte Ausnutzung der Fähigkeiten des CGI.
Das Programm bekommt als Argument den Dateinamen einer HTML-Seite
übergeben. Diese Seite wird nun nach dem Schlüsselwort
<! msql > durchsucht, wobei zwischen msql
und > weiterer Text folgen kann. Wenn dieses Schlüsselwort
gefunden wird, so wird der folgende Text als SQL-Befehl interpretiert
und an mSQL geschickt. Dabei existieren noch die Möglichkeiten
Variable und Indexverweise der Datenbank zu verwalten. Abschließend
ein kleines Beispiel, welches einen Datensatz löscht (aus
[ScG96]).
<! msql connect > <! msql database adressdatenbank > <! msql query "DELETE FROM adressen WHERE Nachname = '$loesch' " ergebnis > <! msql free ergebnis > <! msql close > <HTML> <HEAD><TITLE>Aendern eines Datensatzes</TITLE></HEAD> <BODY> <H1>Der Datensatz <I><!msql print "$loesch"></I> wurde geloescht.</H1> </BODY> </HTML>
Weitere Informationen zu diesem Ansatz finden sich in [And95].
![]()
![]()
![]()
![]()
![]()
Das zweite Beispiel, wie Datenbanken an das WWW angebunden werden können, ist von der verwendeten Hardwareumgebung und der angeschlossen Datenbank fast identisch zu der in dieser Studienaufgabe verfolgten Aufgabe. WEB FM ist eine Schnittstelle zwischen dem Datenbankprogramm FILEMAKER PRO in der Version 3.0 auf einem APPLE-Rechner. Das Datenbankprogramm muß auf dem Server als lokale Anwendung laufen.
WEB FM benutzt den auf APPLE-Umgebungen weit verbreiteten HTTP-Server WEBSTAR und das Common Gateway Interface CGI. Als Schnittstelle zwischen dem Server und dem Datenbankprogramm wird, wie in der später vorgestellten eigenen Lösung, APPLESCRIPT benutzt. Dabei werden die Felder der Datenbank direkt durch die in HTML-Forms gegebenen Variablennamen kodiert. WEB FM bietet insgesamt eine fast vollständige Unterstützung der von FILEMAKER angebotenen Funktionalität.
FILEMAKER PRO V3.0 bietet in dieser Version eine
komplette Anbindung an das APPLESCRIPT - Interface an, was in
der Vorgängerversion V2.1, die für diese Studienarbeit
zur Verfügung stand, nicht gegeben war. Insofern ist es interessant,
die von WEB FM angebotene (kommerzielle) Lösung mit derjenigen
dieser Arbeit zu vergleichen, da sowohl das Datenbankprogramm
als auch die verwendete Schnittstelle fast identisch sind. Nur
beim verwendeten Server bestehen große Unterschiede. Leider
konnte eine Demonstrationsversion von WEB FM bis jetzt nicht getestet
werden, da dem Autor die benötigte neuere Version von FILEMAKER
PRO nicht zur Verfügung stand. Aufgrund der von WEB FM zur
Verfügung gestellten Beispiele läßt sich noch
kein Urteil erlauben, außer daß die von WEB FM entwickelte
Lösung scheinbar beachtlich kurze Antwortzeiten erreicht.
Es ist zu empfehlen, sich die Funktionsweise der von mir entwickelten
Lösung anzueignen und dieses Wissen mit den von WEB FM zur
Verfügung gestellten Informationen zu vergleichen.
Weitere Ansätze
Die vorangegangenen Kapitel sollen nur einige Beispiele aufzeigen, wie die Problemstellung dieser Studienarbeit unter den gleichen oder unter völlig verschiedenen Systemvoraussetzungen angegangen wurde. In der Kürze der Darstellung kann nicht auf jedes Detail eingegangen werden und die vorgestellten Beispiele stellen nur eine Auswahl unter den vorhandenen Ansätzen dar.Insbesondere sei noch auf zwei Artikel [Ber95] und [Per95] verwiesen, die weitere Möglichkeiten zur dynamischen Seitenerzeugung in HTML zeigen, aber auf die hier nicht mehr eingegangen wird.
In diesem Kapitel soll die von mir im Rahmen dieser
Studienarbeit entwickelte Anbindung von Datenbanken und Dokumenten
an den CL-HTTP-Server erklärt werden. Die ersten beiden Kapitel
erläutern kurz die benutzten Grundlagen. Die vorgestellte
Lösung wurde in LISP implementiert, wobei das objektorientierte
CLOS verwendet wurde. In den darauf folgenden Kapiteln werden
die implementierten Klassen dokumentiert und deren Verwendung
an Beispielen erläutert.
![]()
![]()
![]()
![]()
![]()
Im Betriebsystem Version 7.xx von APPLE MACINTOSH wurde das System der AppleEvents eingeführt, durch das mehrere Applikationen in die Lage versetzt werden, miteinander zu kommunizieren. Diese Kommunikation ist nicht nur auf einen Rechner beschränkt, sondern kann auch zwischen vernetzten Rechnern stattfinden. Ein AppleEvent wird immer von einer Applikation zu einer anderen Applikation geschickt, wobei der Sender als Client und der Empfänger als Server bezeichnet wird. Jeder Event besteht aus drei Einzelteilen, der Spezifizierung des Empfängers, des auszuführenden Events und der Daten, die der Server übergeben bekommt.
Der Empfänger eines AppleEvents bestimmt sich aus der sogenannten creator signature. Diese ist ein Kürzel aus vier Buchstaben, die für jedes Applikationsprogramm einmalig ist. Zusätzlich kommt dann eventuell die Adresse des Rechners, auf dem der Server erwartet wird, hinzu.
Der auszuführende Event bestimmt sich aus zwei Teilen, die jeweils durch ein Kürzel mit vier Buchstaben dargestellt werden. Das erste Kürzel stellt die Gruppe ("suite") dar, in die der Event gehört. APPLE hat bis jetzt vier Gruppen definiert, diese gliedern sich vom Allgemeinsten zum Speziellsten: "Required", "Core", "Functional-area", "Custom". Es sind aber auch weitere Gruppen möglich. Das zweite Kürzel ("ID") stellt eine eindeutige Abkürzung für einen Befehl dieser Gruppe dar.
Die Argumente, die man einem Event übergeben
kann, werden in der dritten Gruppe als eine Liste von Kürzeln
(wieder aus 4 Buchstaben) übergeben. Folgendes Beispiel zeigt
einen kurzen Befehl in APPLEEVENTS (aus [Sch94]):
-- holt das dritte Wort des vordersten Textes des Programmes
-- "Scriptable Text Editor"
Server: "quil"
Event: Suite "core" ID "getd"
Data: {----,cwrd,indx,3,cwnd,indx,1,capl,pnam,"Scriptable Text Editor" }
Wie man sieht, sind AppleEvents wegen ihrer Kürze und einfachen Struktur für den Rechner sehr effizient zu handhaben, aber für einen Menschen sind diese Kürzel ungefähr genauso unverständlich wie kompilierter Programmcode, weswegen nur in Ausnahmefällen direkt mit diesen Eventkürzeln gearbeitet wird.
Auf diesen AppleEvents aufbauend arbeitet APPLESCRIPT. APPLESCRIPT ist eine Skriptsprache die sich an der englischen Sprache orientiert. Jedes Programm, das "AppleScript - fähig" ist, verfügt über eine zusätzliche Ressource in Form eines Wörterbuchs ("dictionary"). In diesem Wörterbuch stehen die für diese Applikation gültigen Übersetzungen von englischen Ausdrücken in AppleEvents. APPLESCRIPT besitzt zusätzlich zu den applikations-spezifischen englischen Ausdrücken die für Programmiersprachen üblichen Kontrollstrukturen wie Schleifen, bedingte Anweisungen und Variablen. Ein Skript wird somit übersetzt, in dem der Text nach den Kontrollstrukturen aufgelöst wird und alle Event-Befehle in dem für den jeweiligen Event - der ja eindeutig festgelegt ist - zuständigen Wörterbuch umgesetzt wird. Das Ergebnis ist dann eine Folge von AppleEvents. Durch die Kontrollstrukturen wird APPLESCRIPT zur vollwertigen Programmiersprache und durch eine geschickte Wahl der Befehlsnamen wird erreicht, daß die Skripten einen durchaus verständlichen englischen Text ergeben.
Folgende Nachteile von APPLESCRIPT sollen an dieser
Stelle erwähnt werden:
Das Beispiel ist von der Funktionalität identisch
zum letzten Beispiel, nur diesmal als APPLESCRIPT:
-- holt das dritte Wort des vordersten Textes des Programmes
-- "Scriptable Text Editor"
tell application "Scriptable Text Editor" to get word 3 of window 1
-- dasselbe als Liste von Eventkürzeln zum Vergleich
Server: "quil"
Event: Suite "core" ID "getd"
Data: {----,cwrd,indx,3,cwnd,indx,1,capl,pnam,"Scriptable Text Editor" }
APPLESCRIPT bietet bei der Kompilierung von Skripten
die Möglichkeit, entweder nur Programme zu erzeugen oder
zusätzlich zum Programmcode den Quelltext zu erhalten. Desweiteren
existieren Möglichkeiten der Fehlerbehandlung, falls ein
Event nicht ausgeführt werden kann. Damit läßt
sich der Fehler abfangen und das Skript an einem definierten Punkt
fortsetzen. Als eine Einführung in APPLESCRIPT ist [Sch94]
zu empfehlen: dort finden sich für den Interessierten weitere
Verweise.
![]()
![]()
![]()
![]()
![]()
AppleScript-for-Lisp ist ein Paket für MCL, das eine Benutzung von APPLESCRIPTS aus LISP heraus gestattet. Entwickelt wurde dieses Paket von Tom Bonura von APPLE. Für MCL3.0 wird AppleScript-for-Lisp mitgeliefert, aber es ist auch unter MCL2 lauffähig. Dazu werden zusätzlich die beiden Pakete "osa.lisp" und "aestuff.lisp" benutzt, auf die an dieser Stelle nicht eingegangen werden kann. AppleScript-for-Lisp stellt dabei die Klasse Applescript-object zur Verfügung.
Folgende Vorgehensweise ist beim Benutzen der Klasse üblich:
Zuerst muß eine Instanz der Klasse angelegt werden. Das auszuführende Skript wird als String im Slot "script" abgelegt. Danach kann das Skript kompiliert und ausgeführt werden. Das Ergebnis des Skriptes erhält man als String durch die Methode "the-result-string". Es gibt aber auch die Möglichkeit, das Ergebnis in der Originalform, d.h. in Form von Pointern, zu verarbeiten. Zusätzlich kann man auch Skripten aufnehmen, in dem man eine gewünschte Befehlsfolge am Rechner ausführt; die daraus entstehenden Events werden mitprotokolliert und gespeichert.
Die Benutzung von Applescript-for-Lisp soll an folgendem
Beispiel gezeigt werden:
;;holt den ersten Eintrag der Datenbank "Adressen" des Programms "FileMaker Pro"
(defparameter beispiel
(make-instance 'applescript-object)) ;erstellt die Instanz
(setf (script beispiel) ;das auszuführende Skript
(format NIL
"tell application \"FileMaker Pro\" ~%~
get record 1 of Document \"Adressen\" ~%~
end tell"))
(compile-applescript beispiel) ;kompiliert und führt das Skript aus
(execute-applescript beispiel)
(print (the-result-string beispiel)) ;zeigt das Ergebnis an
;;Ergebnis {"Paulchen","Panther","23","Auf der Leiter 35","90107","Ameisenhausen"}
Wie man an diesem Beispiel sieht, erhält man
das Ergebnis eines Skripts in der gleichen Form, wie ein APPLESCRIPT
es zurückgibt. Nur wäre es in diesem Fall wünschenswert,
daß das Ergebnis die Form einer LISP-Liste hätte, damit
es weiterverarbeitet werden kann. Diese Funktionalität wird
unter anderem in der entwickelten Klassenbibliothek bereitgestellt,
die einen komfortablen Zugang zu APPLESCRIPT implementiert.
![]()
![]()
![]()
![]()
![]()
Das folgende Kapitel stellt die Klassen vor, die
als Erweiterung aus der Klasse AppleScript-Object abgeleitet
wurden. Es wird auf die grundlegenden Techniken und Ideen, aber
nicht auf Details der Implementierung eingegangen werden. Für
die Anwendung dieser Klassen werden jeweils Beispiele gegeben.
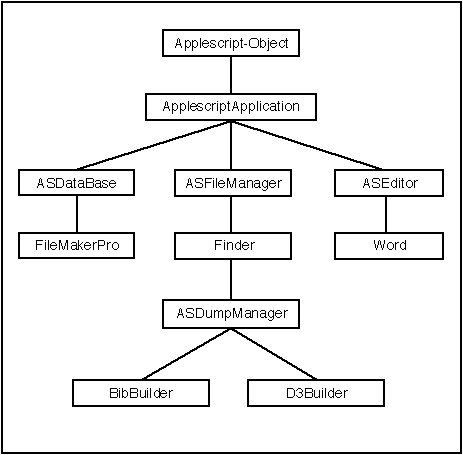
Die Vererbungshierarchie wird in folgender Abbildung dargestellt:
![]()
![]()
![]()
![]()
![]() 3.3.1. Die Klasse AppleScriptApplication
3.3.1. Die Klasse AppleScriptApplication
Wie im Kapitel 3.2 Über AppleScript-for-LISP
festgestellt wurde, stellt die Klasse Applescript-object,
grundlegende Mechanismen für APPLESCRIPTS zur Verfügung.
Allerdings sind diese Mechanismen für eine häufige Verwendung
zu unkomfortabel und zu aufwendig zu bedienen. Um dies zu erreichen,
wurde die Klasse AppleScriptApplication aus der Klasse
Applescript-object abgeleitet. Mit dieser Klasse sollen
folgenden Ziele erreicht werden:
Es ist vorgesehen, pro Instanz dieser Klasse eine Applikation oder maximal ein zu einer Applikation gehörendes Dokument zu verwalten. Diese Begrenzung ist sinnvoll, da sich so in einer Instanz viele Eigenschaften eines Dokumentes (wie z.B. die Namen der Felder einer Datenbank) speichern lassen. Für die Verwaltung mehrerer Dokumente derselben Applikation müssen mehrere Instanzen der Klasse angelegt werden. Bei der Initialisierung wird diese Applikation gestartet und das Dokument geladen.
Die in dieser Klasse bereitgestellten Skripten zum Starten von Programmen, Laden, Speichern und Schließen von Dateien, und zum Beenden von Programmen werden wegen ihrer Kürze nicht sofort ausgeführt, sondern nur an das bereits bestehende Skript angefügt. Durch längere Skripten entsteht weniger Aufwand beim Kompilieren und Ausführen der APPLESCRIPTS als durch viele sehr kleine Skripten. Die in dieser Klasse bereitgestellten Skripten müssen also noch kompiliert und ausgeführt werden.
Es existiert ein Schalter, um festzulegen, ob der Benutzer Skripten ausführen darf, die Änderungen im Dokument bewirken. Wenn diese Berechtigung nicht vorliegt, kann der Benutzer keine Skripten ausführen, die bestimmte, applikationsspezifische Befehle beinhalten. Diese Befehle werden bei der Definition der Klasse festgelegt und beinhalten die Befehle, mit denen Daten geändert, erzeugt oder gelöscht werden können.
Desweiteren läßt sich festlegen, ob das Skript auf einem fremden Rechner ausgeführt werden soll. Damit dies geschehen kann, muß man den Namen des Rechners, einen Benutzernamen und dessen Passwort mitteilen. Der Benutzer und das Passwort müssen auf dem fremden Rechner eingetragen sein und es muß vom fremden Rechner die Erlaubnis, Programme auf diesem Rechner auszuführen, erteilt werden. Dies läßt sich unter Programmverbindungen im Systemmenü von APPLE einstellen. Das Ausführen von AppleScripts auf fremden Rechnern beruht auf der Technik, daß AppleEvents über ein Netz versendet werden und vom Empfänger ausgeführt werden können [Sch94]. Für das Ausführen werden allerdings Erweiterungen zu APPLESCRIPT benötigt (sog. Scripting Additions), die die Verbindung zu einem anderen Rechner ohne explizite Eingabe eines Passwortes ermöglichen. Dabei ergibt sich das Sicherheitsproblem, daß Passwörter offen in das entsprechende Skript geschrieben werden müssen.
Wenn ein Skript ausgeführt worden ist, muß als nächstes das Ergebnis des Skriptes behandelt werden. Wie schon im letzten Kapitel gezeigt, erhält man in vielen Fällen ein Ergebnis, das man direkt in LISP nicht benutzen kann, da es als String vorliegt, egal welcher Datentyp es tatsächlich ist. Dazu wurde eine Konvertierungsroutine implementiert, die die in APPLESCRIPT eingebauten Datentypen wie Zahlen, Texte, Listen und Structs in die entsprechende Typen in LISP übersetzt. Dazu wird die Möglichkeit gegeben, das Ergebnis oder Teile davon als Binärdatei abzuspeichern. Dies bietet sich z.B. an, wenn das Ergebnis ein Bild ist.
Zum Abschluß soll das Beispiel aus dem letzten
Kapitel noch einmal benutzt werden, nur diesmal unter der Verwendung
der neuen Klasse.
;;holt den ersten Eintrag der Datenbank "Adressen" des Programms "FileMaker Pro"
(defparameter beispiel
(make-instance 'AppleScriptApplication
:Title "Beispiel"
:application-name "FileMaker Pro"
:FileName "Adressen"
)) ;erstellt die Instanz
(AppleScriptApp_Init beispiel) ;Initialisiert die Instanz, startet
;notfalls die Applikation
;und öffnet die Datenbank
(AppleScriptApp_NewScript beispiel) ;erzeugt ein neues Skript
(AppleScriptApp_tell beispiel ;erzeugt den Skripttext
"get record 1 of Document \"Adressen\" ")
(AppleScriptApp_ExecuteScript beispiel) ;kompiliert und führt das Skript aus
(AppleScriptApp_GetResult beispiel
:Outputformat 'LI TYPE=DISCST) ;zeigt das Ergebnis an
;;Ergebnis ("Paulchen" "Panther" "23" "Auf der Leiter 35" "90107" "Ameisenhausen")
Wie man sieht, hat das Ergebnis jetzt das für
die weitere Verwendung angenehmere Format einer Liste von Strings.
Benötigt wird noch die Eigenschaft, daß das System
bereits weiß, daß jeder Eintrag im Dokument "Adressen"
aus sechs Elementen besteht (nämlich "Vorname",
"Name", "Alter", "Strasse", "Postleitzahl"
und "Ort"), wobei "Alter" und "Postleitzahl"
Zahlen, die anderen Zeichenketten darstellen. Wenn dieses Wissen,
welches in der Datenbank gespeichert ist, auch in LISP vorhanden
ist, können die Einträge auch gleich in das richtige
Format konvertiert werden.
![]()
![]()
![]()
![]()
![]() 3.3.2. Die Klassen ASDataBase
und FileMaker
3.3.2. Die Klassen ASDataBase
und FileMaker
Am Ende des letzten Abschnitts wurde gezeigt, daß
durch die Klasse AppleScriptApplication schon ein sehr
mächtiges und allgemein verwendbares Werkzeug zur Steuerung
von Applikationen vorliegt. Es hat sich ebenfalls herausgestellt,
daß dieses Werkzeug für die angenehme Steuerung von
Programmen noch zu allgemein ist, und daß weitere Spezialisierung
notwendig ist. Deshalb wurde die Klasse ASDataBase geschaffen,
die für die Anbindung von Datenbanken gedacht wurde. Diese
Klasse stellt eine Oberklasse für alle konkreten "AppleScript-fähigen"
Datenbankprogramme dar. In dieser Klasse werden nur Slots und
Methoden zur Verfügung gestellt, die unabhängig von
konkreten AppleScripts sind. Durch diese Trennung wird es ermöglicht,
verschiedene Datenbankprogramme mit den gleichen Mechanismen zu
verwalten. Als Beispiel für ein konkretes Datenbankprogramm
wurden im nächsten Schritt die in ASDataBase vereinbarten
Skripten für das Programm FILEMAKER PRO in der Klasse FileMaker
implementiert. Da in dieser Klasse nur die in ASDataBase
eingeführten Methoden vollständig implementiert wurden,
soll auf diese Klasse nicht detailliert eingegangen werden.
Aufgaben der Klasse
Wenn im oberen Abschnitt behauptet wurde, alle "AppleScript-fähigen" Datenbankprogramme lassen sich mit dieser Klasse verwalten, so ist an dieser Stelle zuerst eine Einschränkung dieser Behauptung zu machen: objektorientierte Datenbanken lassen sich nur unter dem Verzicht gewisser Eigenschaften benutzen. Dies hat im Wesentlichen zwei Gründe:
Zum einen war es ein wichtiges Ziel dieser Studienarbeit, die Datenbank FILEMAKER PRO, die nicht objekt-orientiert ist, an Lisp anzubinden. Deshalb wurde ausschließlich mit diesem Programm gearbeitet. Ein objektorientiertes, durch APPLESCRIPTS steuerbares Datenbankprogramm stand nicht zur Verfügung.
Grund zum Zweifel an der Anbindung solcher Programme
liefert nämlich zum Zweiten die Struktur von APPLESCRIPT
und dessen Datentypen. Diesen fehlt die Möglichkeit Objekte
als solches darzustellen. Vor allem Vererbungen und Zeiger auf
andere Objekte sind nicht vorhanden. Die volle Ausnutzung objektorientierter
Möglichkeiten erscheint hier sehr schwer zu erreichen und,
wenn überhaupt, nur über größere, "AppleScript-untypische"
Umwege.
Datenbanken haben im Allgemeinen folgende gemeinsame
Eigenschaften, die durch die Klasse bereitgestellt werden.
Für diese Anforderungen stellt die Klasse ASDataBase
die erforderlichen Slots und die abstrakten Methoden zur Verfügung.
Die Klasse FileMaker füllt die Methoden mit den für
FILEMAKER PRO korrekten APPLESCRIPTS aus. Als Beispiel dient an
dieser Stelle wieder die in den letzen beiden Abschnitten verwendete
Aufgabe.
;;holt den ersten Eintrag der Datenbank "Adressen" des Programms "FileMaker Pro"
(defparameter beispiel
(make-instance 'FileMaker ;erstellt die Instanz
:Title "Beispiel"
:application-name "FileMaker Pro"
:FileName "Adressen"
))
(AppleScriptApp_Init beispiel) ;Initialisiert die Instanz,
;startet notfalls die Applikation,
;öffnet die Datenbank
;holt den Namen der Datenbank,
;das aktuelle Layout,
;die Namen und Typen der Felder
;aus der Datenbank
(ASDataBase_GetRecord beispiel 1) ;holt den Eintrag mit Nummer 1
;;Ergebnis ( "Paulchen" "Panther" 23 "Auf der Leiter 35" 90107 "Ameisenhausen" )
Wie man sieht, hat das Ergebnis jetzt das gewünschte Format.
Bis jetzt wurde eine der wichtigsten Eigenschaften von Datenbanken, nämlich die Suche nach Datensätzen, noch nicht behandelt. Jedes Datenbankprogramm enthält neben den Mechanismen zum Erstellen und Verwalten von Datensätzen auch geeignete, meist durch interne Indexierungen sehr effiziente, Suchmethoden. Für jedes Feld läßt sich ein Suchmuster bestimmen, das abhängig vom Typ des Feldes sein kann. Für ein Textfeld kann man z.B. unterscheiden, ob ein Suchmuster mit dem Eintrag identisch sein muß oder ob das Muster nur im Eintrag vorkommen kann. An welcher Stelle dieses Muster auftreten darf (z.B. am Anfang oder Ende) oder ob Groß- und Kleinschreibung zu beachten ist, läßt sich im Allgemeinen ebenfalls festlegen. Die meisten Datenbankprogramme bieten dazu noch eine Möglichkeit, reguläre Ausdrücke zu verwenden. Ähnliche Erweiterungen der Suche lassen sich für Zahlen oder Datumsangaben machen, während man für Bilder oder Töne keine Suchmuster angeben kann. Zusätzlich können mehrere Suchanfragen verknüpft werden, so daß man z.B. nach allen Einträgen suchen kann, die das eine Muster und / oder das andere Muster enthalten, oder man kann ein Suchmuster angeben, wobei alle Einträge gesucht werden, die nicht auf das Suchmuster passen.
Allerdings traten an dieser Stelle große Probleme
im Zusammenhang mit dem verwendeten Programm FILEMAKER PRO in
der Version V2.1 auf. Es war nicht möglich, mittels APPLESCRIPTS
eine Suchanfrage in diesem Programm zu setzen. Insbesondere ergab
sich das Problem, daß man aus LISP die gewünschten
Suchmuster in die Suchabfrage von FILEMAKER PRO übertragen
will. Genau für diese Suchanfrage existiert aber keine Ansteuerungsmöglichkeit.
Dies scheint ein Fehler in der verwendeten Version des Programms
zu sein, der in der aktuellen Version V3 behoben worden ist. Diese
stand leider nicht zur Verfügung. Aus diesem Grund mußte
eine andere, weniger elegante und effiziente Lösung entwickelt
werden.
Suche in der Klasse ASDataBase
Die für die Suche verwendete Technik besteht darin, den kompletten Inhalt der Datenbank in LISP zu importieren und die Suche durch LISP-Funktionen durchzuführen. Diese Idee besitzt zwei große Nachteile. Zum einen verdoppelt man dadurch die Datenbank, die jetzt in LISP und im Datenprogramm vorhanden ist, was vor allem bei großen Datenbanken eine Speicherbelastung darstellt, und zum anderen benötigt der Export der Daten Zeit. Da dieser Export aber nur sehr selten, nämlich beim Wechsel eines Layouts oder beim Verändern der Datenbank, durchgeführt werden muß, kann man diesen Aufwand noch rechtfertigen.
Das Problem der Speicherbelastung ist allerdings gravierender. Während bei sehr großen Datenbanken die einzelnen Datenbankprogramme meist Mechanismen besitzen, nicht alle Daten im Speicher zu halten, sondern nur bei Bedarf vom Speichermedium zu laden, wäre in diesem Fall das LISP-System überfordert. Die Idee ist nur hinter dem Hintergrund vertretbar, daß für diese Programmversion keine andere Lösung gefunden werden konnte. Durch diese Lösung ist im Prinzip der Einsatz der Datenbank überflüssig, da die notwendigen Daten im LISP-System vorhanden sind. Da die gefundene Lösung nur als Notlösung gedacht ist, die bei Verwendung der Nachfolgerversion von FILEMAKER PRO überflüssig wird, wurde auf die Benutzung der Datenbank nicht verzichtet.
Nicht verschwiegen soll, daß durchaus auch
Vorteile aus dieser Lösung entstehen. Dadurch daß die
Suchfunktionen selbst implementiert wurden, konnte eine flexiblere
Gestaltung der Suchmuster erreicht werden, als es FILEMAKER PRO
anbietet. Das Programm unterstützt - unverständlicherweise
- nicht die Unterscheidung nach Groß- und Kleinschreibung
in einer Zeichenkette und bietet nur eingeschränkte Möglichkeiten
bei der Verknüpfung mehrer Suchanfragen. Dies konnte durch
die eigenen Funktionen behoben werden. So werden folgende Möglichkeiten
zur Verknüpfung angeboten:
Werden mehr als zwei Suchanfragen miteinander verknüpft,
so werden die Anfragen von vorne nach hinten miteinander verknüpft.
Zuerst werden die beiden ersten Anfragen verknüpft, das Ergebnis
sodann mit der der dritten Anfrage, usw.
Bereitstellung von HTML-Seiten
Nachdem so die Anbindung an Datenbankprogramme hergestellt
worden ist, stellt sich als nächstes die Aufgabe, die Anbindung
zum HTTP-Server-Programm zu realisieren. Der Server wird in Abschnitt
3.4.1 Über CL-HTTP vorgestellt. Die dafür implementierten
Funktionen wurden in der Klasse ASDataBase bereitgestellt,
so daß die erzeugten HTML-Seiten und die dazugehörige
Funktionalität unabhängig vom konkreten Datenbankprogramm
und von APPLESCRIPT ist. Im Speziellen wurden für folgende
Aufgaben HTML-Seiten bereitgestellt:
Beim Initialisieren einer Anbindung werden diese
Seiten automatisch dem Server bekannt gegeben. Dies hat den Vorteil,
daß beim Neuanlegen von Anbindungen sofort diese Seiten
zur Verfügung stehen und benutzt werden können. Diese
Seiten sind über eine spezielle Einstiegsseite erreichbar.
Es besteht weiterhin die Möglichkeit diese Standardseiten
mit eigenen LISP-Funktionen zu überschreiben, doch darauf
soll erst im Kapitel 3.4 Benutzung der Klassen zusammen mit CL-HTTP
eingegangen werden.
![]()
![]()
![]()
![]()
![]() 3.3.3. Die Klassen ASEditor und
Word
3.3.3. Die Klassen ASEditor und
Word
Neben Datenbanken stellen Textdokumente eine zweite
Möglichkeit dar, Informationen zu speichern. Allerdings ist
die Art der Information anders als bei Datenbanken. Textinformationen
lassen sich in Absätzen zusammenfassen, es gibt keine so
klaren Zuordnungen wie in Datenbanken. Daher lassen sich keine
äquivalenten Mechanismen schaffen, wie sie beim Erzeugen
und Verwalten von Datensätzen einer Datenbank vorhanden sind.
Auch bei der Suche stehen weniger Möglichkeiten zur Verfügung,
da im Wesentlichen nur nach Textmustern gesucht werden kann. Nichtsdestoweniger
ist diese Volltextsuche im allgemeinen zeitaufwendiger, da weniger
Indizierungsmöglichkeiten für den Text bestehen.
Aufgaben der Klasse ASEditor
Aufgrund der Besonderheiten von Textinformationen wurde die Klasse ASEditor zur Steuerung von Texteditoren und ihren Dokumenten geschaffen. Als konkrete Anwendung wurde durch die Klasse Word die Textverarbeitung MICROSOFT WORD 6.0 angebunden. Dabei wurde schon wie im vorherigen Kapitel so verfahren, daß für alle Texteditoren gültige Eigenschaften in der Klasse ASEditor vereinbart wurden. Dies ist vor allem die Eigenschaft, daß mehrere Textdokumente sich gleichzeitig von einem Programm verwalten lassen. Die Dokumente sind durch ihren Namen unterscheidbar.
Ein einfaches Beispiel für APPLESCRIPTS mit
dieser Klasse zeigt die Zusammenarbeit von LISP, APPLESCRIPT und
WORDBASIC. Die vorgestellte Funktion fügt den als Argument
übergebenen Text in das vorderste WORD-Dokument ein:
;Einfügen von Text in Word-Dokumente
(defmethod ASEditor_Insert ((self Word) (text string))
(AppleScriptApp_NewScript self)
(AppleScriptApp_tell self (format NIL
"tell front Document~%~ ;vordersters Dokument
do script \"Einfügen \\\"~a\\\" \"~%~ ;Aufruf des WordBasic-Befehls
end tell"
text ))
(AppleScriptApp_ExecuteScript self) ;Ausführen
(AppleScriptApp_GetResult self :OutPutFormat 'string)) ;Ergebnis ist wieder der eingefügte Text
;Aufruf
(ASEditor_Insert bsp "Dies ist ein Versuch")
Bei der Suche lassen sich folgende Erweiterungen machen. Das Suchmuster kann auf passende Groß- und Kleinschreibung eingestellt werden, man kann das Suchmuster als ganzes Wort verlangen, d.h. vor und hinter dem gefunden Text müssen Leerzeichen, Zeilen- oder Satztrenner stehen, und es lassen sich Suchmuster durch reguläre Ausdrücke erweitern. MICROSOFT WORD besitzt eine eigene sehr mächtige Skriptsprache, WORDBASIC, die sich von APPLESCRIPT aus benutzen läßt. Für eine Einführung in WORDBASIC sei auf [Wor92] verwiesen.
Dabei existieren einige unverständliche Schönheitsfehler in der Zusammenarbeit der beiden Skriptsprachen. Während APPLESCRIPT einen eher funktionalen Ansatz verfolgt, d.h. jede Anweisung sollte ein Ergebnis liefern, geht WORDBASIC eher von Prozeduren, die kein Ergebnis liefern, aus. Wenn man eine Suche in WORD startet, so läßt sich diese über ein WORDBASIC-Programm ausführen. Allerdings kann dieses Programm kein Ergebnis zurückgeben, so daß nichts über den Erfolg der Suche zurückgegeben werden kann. Um dieses Problem zu beheben, mußte der Umweg beschritten werden, das gefundene Suchergebnis zuerst in eine Datei zu schreiben und diese hinterher wieder auszulesen.
Der in der Textverarbeitung mit verschiedenen Stilen
und Formatierungen versehene Text wird dabei ohne diese Besonderheiten
behandelt. Dies wäre anders auch nicht realisierbar. Das
bedeutet aber zugleich, daß man das Suchergebnis als reinen
ASCII-Text erhält, der zwar den gleichen Inhalt, aber eine
andere Form als das Original besitzt.
Bereitstellung von HTML-Seiten
Es wurde für eine Kopplung zwischen Suchanfragen
und dem HTTP-Server gesorgt, wobei in diesem Fall nur für
die folgenden beiden Fälle Seiten eingerichtet werden:
Beim Initialisieren einer Anbindung werden diese
Seiten wiederum automatisch dem Server bekannt gegeben.
![]()
![]()
![]()
![]()
![]() 3.3.4. Die Klassen ASFileManager
und Finder
3.3.4. Die Klassen ASFileManager
und Finder
Eine dritte Möglichkeiten, Informationen zu speichern, ist die Speicherung in Dateien, wobei keine Annahme darüber gemacht wird, in welchem Format diese gespeichert sind. Demzufolge kann man den Inhalt der Dateien nicht direkt ansehen, sondern dem Benutzer zu dessen eigenen Verwendung zur Verfügung stellen. Falls diese Dateien ausführbare Programme darstellen, so können diese am Server ausgeführt und das Ergebnis angezeigt werden. Insbesondere lassen sich diese Dateien in Verzeichnishierarchien ordnen, durch die der Benutzer wandern und die von ihm gewünschten Dateien suchen kann.
Diese Möglichkeiten der Dateiverwaltung wurden in einer dritten Klasse realisiert. Dabei wurde wiederum so verfahren, daß eine Klasse - in diesem Fall ASFileManager allgemeine Mechanismen zur Verfügung stellt, und die konkrete Implementierung für ein spezielles Dateiverwaltungsprogramm in einer Unterklasse Finder angeboten werden. APPLE´S FINDER ist eigentlich viel mehr als ein Dateiverwaltungsprogramm, es stellt die graphische Benutzeroberfläche von APPLE dar.
An dieser Stelle läßt sich in einem einfachen Beispiel nichts Neues zeigen, so daß auf ein Beispiel verzichtet werden kann.
Da man für den Client nicht alle Dateien auf dem Server zugänglich machen will, wurde so verfahren, daß sich ein Wurzelverzeichnis definieren läßt, auf dessen Unterverzeichnissen zugegriffen werden kann, welches aber nicht verlassen werden kann. In dieser Beziehung ist die entwickelte Lösung ähnlich zu dem in Kapitel 2.2 Common Gateway Interface vorgestellten Konzept.
Für die Anbindung an den HTTP-Server wurden
zwei Seiten entwickelt. Die erste erlaubt das Ausführen von
Programmen innerhalb einer gegebenen Hierarchie. Diese Programme
werden auf dem Server gestartet. Dabei wurde darauf verzichtet,
einen Mechanismus zu implementieren, der es erlaubt, Argumente
an diese Programme zu übergeben. Ebenfalls muß beachtet
werden, daß die Programme keine Eingaben vom Benutzer verlangen,
da die Eingaben auf dem Server erscheinen würden. Als Programme
sind vor allem APPLESCRIPTS denkbar, da diese klein genug sind,
und somit den Server wenig belasten. Die zweite Anbindung erlaubt
das Kopieren von Dateien vom Server zum Client (sog. "Download").
Wenn der Benutzer die Berechtigung dazu besitzt, wird es ihm zusätzlich
gestattet, Dateien zu kopieren, löschen oder umzubenennen.
Damit wird ein ähnliches System angeboten, wie es FTP erlaubt.
Von einem FTP-Server hat der Client die Möglichkeit, Dateien
auf seinen eigenen Rechner zu laden. Besondere Benutzer, die sich
über ein Passwort identifizieren müssen, haben dazu
die Möglichkeit, Dateioperationen durchzuführen oder
Dateien auf dem Server abzulegen. Das Laden von Dateien vom Client
auf den Server (sog. "Upload") wurde allerdings
in der vorgestellten Lösung nicht implementiert, da es einen
zu großen Aufwand erfordert hätte.
![]()
![]()
![]()
![]()
![]() 3.3.5. Die Klassen ASDumpManager,
D3Builder und BibBuilder
3.3.5. Die Klassen ASDumpManager,
D3Builder und BibBuilder
Diese drei Klassen wurden geschaffen, um die Erstellung und Verteilung von Dumps zu erreichen. Für die Verwaltung des Dateisystems, in dem die Dumps gespeichert werden, werden viele der Funktionen benötigt, die in der Klasse ASFileManager geschaffen wurden. Deshalb wurden die Klassen von dieser abgeleitet. Wie schon bei den bisherigen Klassen wurde so verfahren, daß eine abstrakte Klasse - ASDumpManager - geschaffen wurde, die allgemeine Routinen enthält, während die zwei aus dieser Klasse abgleiteten Klassen D3Builder und BibBuilder die konkreten Anwendungen realisieren.
Die Klassen haben im wesentlichen zwei Hauptaufgaben, das Erstellen und das Verteilen von Dumps, welche im folgenden genauer beschrieben werden.
Erstellen von Dumps
Ein neuer Dump wird dadurch erstellt, daß man
eine gegebene LISP-Grundbibliothek startet und zu dieser weitere
Funktionen oder Klassen compiliert. Das dadurch entstehende System
speichert man als Dump ab. Dabei existieren folgende Schwierigkeiten,
die durch das entwickelte System behandelt werden:
Für das Erstellen eines Dumps konnten wiederum
APPLESCRIPTS benutzt werden. Eine wichtige Rolle spielte dabei
die Möglichkeit, APPLESCRIPTS auf einem anderen Rechner auszuführen.
Dadurch konnte es ermöglicht werden, daß der Dump auf
einem anderen, nicht benutztem Rechner gebaut wird. Die Zeitsteuerung
der Erstellung und die Benutzung von Mailing-Listen wurde durch
Routinen ermöglicht, die von Christoph Oechslein im Rahmen
seiner parallel zu dieser erstellten Studienarbeit geschaffen
wurden. Aus diesem Grund wird auf diese Funktionen nicht weiter
eingegangen, sondern auf diese Studienarbeit verwiesen [Oec96].
Die Bedienung erfolgt über HTML-Seiten. Das
bedeutet, daß zur Bedienung ein Browser ausreicht und die
Aufträge zur Dumperstellung vom Server verwaltet werden.
Dadurch konnte schnell eine einfach zu bedienende Oberfläche
geschaffen werden. Für die Erstellung von Dumps werden folgende
HTML-Seiten angeboten:
Nachdem ein Dump erstellt und auf das Archivmedium
kopiert worden ist, werden Methoden benötigt, diesen Dump
den daran interessierten Programmierern zur Verfügung zu
stellen. Dafür wurden zwei Ansätze entwickelt:
Ein Entwickler kann sich Informationen über
die vorhandenen Dumps anzeigen lassen und aufgrund dieser Informationen
seine Auswahl treffen. Der gewählte Dump wird dann auf seinen
Rechner kopiert, wobei je nach Art des Dumps eine gewisse Verzeichnisstruktur
eingehalten werden muß. Dafür wurden ebenfalls HTML-Seiten
erstellt. Eine einfache Variante kopiert den aktuellsten Dump
im Archiv auf den Rechner des Benutzers. Dies ermöglicht
wiederum eine unkomplizierte und extrem vereinfachte Bedienung
durch einen einzigen Mausklick. Die zweite Möglichkeit ist
im Prinzip ähnlich zu dem im Kapitel 3.3.4 Die Klassen ASFileManager und Finder vorgestellten FTP-Anwendung, nur daß für
eine dem Problem angepassten Oberfläche gesorgt wurde. Es
wird ebenfalls ein Wurzelverzeichnis, in diesem Fall das Startverzeichnis
des Archivs, angegeben, innerhalb dessen ein geeignetes Objekt
gewählt werden kann. Je nach Art des Dumps sind in diesem
Fall aber auch schon bestimmte Unterverzeichnisse einzelne Objekte,
die kopiert werden sollen. Die Verzeichnisstruktur innerhalb dieses
Objektes ist nicht von Interesse, so daß sie nicht angezeigt
werden braucht. Zum Beispiel besteht ein D3-Dump aus dem Dump
selbst und mehreren in Unterverzeichnissen zusammengefassten Quelldateien.
Von Interesse ist aber nur, entweder alles zu kopieren oder ein
bestimmtes Unterverzeichnis namens "Patches", das die
kompilierten Änderungen enthält.
Der zweite Anwendungsbereich des Verteilens entsteht
direkt nach dem Erstellen eines Dumps. Zuerst wird der neue Dump
auf das Archivmedium kopiert, um dort gespeichert zu werden. Für
diejenigen Entwickler, die in der für diesen Dump vorhandenen
Mailingliste vertreten sind, ist dieser Dump ebenfalls von Interesse.
Deshalb ist es wünschenswert, wenn der neue Dump automatisch
auf ihre eigenen Rechner kopiert wird. Dazu müssen sie beim
Anmelden in dieser Mailingliste angeben, auf welchen Rechner ein
Dump kopiert werden soll. So kann jeder Entwickler auch mehrere
Rechner für einen neuen Dump registrieren lassen. Diese Registrierung
kann er zu einem späteren Zeitpunkt noch ändern oder
löschen. Nach der Erstellung eines neuen Dumps muß
dieser auf eine gewisse Anzahl von Rechnern, die sich durch die
Anmeldung der Entwickler für bestimmte Dumps bestimmen, kopiert
werden. Das Kopieren selbst erfolgt wiederum durch Ausführen
von APPLESCRIPTS auf diesen Rechnern.
Einstellungen und Konfiguration
Für das Erstellen und das Verteilen von Dumps müssen bestimmte Vereinbarungen über die Struktur der Verzeichnisse sowohl auf dem Archivmedium als auch auf den einzelnen Rechnern der Entwicklern getroffen werden. Dabei wird davon ausgegangen, daß diese Struktur auf allen Rechner gleich sein soll, d.h. Dumps befinden sich in einem festgelegten Abschnitt der Verzeichnishierarchie, Bibliotheken in einem anderen. D3-Dumps auf den einzelnen Rechnern sind z.B. als Unterverzeichnisse im Verzeichnis "Dumps" abgelegt, wobei die Unterverzeichnisse mit "D3" beginnen. Bibliotheken auf der Archivplatte unter dem Pfad "Dumps/Bibliotheken" zu finden sind.
Desweiteren müssen Default-Einstellungen für das Erstellen von Dumps vereinbart werden. Diese Vereinbarungen sollen aber auch einstellbar sein. Für diesen Zweck wurde eine weitere HTML-Seite implementiert, die diese Funktionalität verwirklicht. Bei einer sinnvollen Wahl der Default-Einstellungen wird es somit möglich, mit einem einzigen Mausklick das Erstellen eines Dumps anzustoßen, ohne weitere Einstellungen vornehmen zu müssen.
Ebenso muß festgelegt werden, welche Rechner
und welche Entwickler an welchen Projekten beteiligt sind. Da
die einzelnen Projekte nach den verschiedenen Mailinglisten geordnet
sind, müssen sich Rechnernamen und email-Adressen für
jede Mailingliste an- und abmelden lassen. Diese Einstellungen
lassen sich sowohl über HTML-Seiten als auch über email
vornehmen.
![]()
![]()
![]()
![]()
![]()
In diesem Kapitel wird zuerst auf das Serverprogramm
CL-HTTP eingegangen. Danach werden verschiedene Zusätze zu
den im letzten Kapitel vorgestellten Klassen vorgestellt, die
verschiedene Dienste zwischen den Klassen und dem Server implementieren.
Ein HTTP-Server stellt ein Programm dar, daß die im HTTP-Protokoll festgelegten Eigenschaften realisiert. In der Zusammenarbeit mit der Darstellungssprache HTML bildet dieses Protokoll die Grundlage des WWW. Für die verschiedensten Rechnerplattformen und Zielsetzungen wurden Server entwickelt. Der Common LISP Hypermedia Server (CL-HTTP) wurde durch John C. Mallery am Massachusetts Institute of Technology (MIT) im Rahmen des "Intelligent Information Infrastructure Project" entwickelt. Wie der Name schon sagt, ist dieser Server in LISP geschrieben. Es existieren Versionen dieses Servers für verschiedene Plattformen. Die in dieser Studienarbeit benutzte Version verwendet MCL 3.0 auf einem Apple MacIntosh-Rechner.
Das allgemeine Ziel hinter der Entwicklung von CL-HTTP war es nach [Clh96], eine Verbindung zwischen den Forschungsgebieten der Künstlichen Intelligenz (KI) und den verteilten Hypermedia-Systemen zu schaffen. Da das WWW und die von ihm bereitgestellten Informationen ständig wachsen, wird es immer notwendiger intelligente Methoden zum Erhalt, zum Vertrieb, zur Filterung und zur Analyse dieser Informationen einzusetzen. CL-HTTP ist vollständig in der Programmiersprache LISP geschrieben.
CL-HTTP bietet folgende Möglichkeiten, die zum
Standardumfang eines Servers gehören:
Die wichtigste Eigenschaft von CL-HTTP ist die Verwendung von LISP-Funktionen zur dynamischen Seitenerzeugung.
Daneben bietet CL-HTTP eine Reihe von Möglichkeiten, auf die an dieser Stelle nicht weiter eingegangen werden kann. Eine detaillierte Beschreibung findet sich in [Clh96].
Da der Server in Common-LISP implementiert wurde, konnten die Möglichkeiten, die objekt-orientiertes Programmieren bieten, genutzt werden. Die verschiedenen URLs (z.B. für Dateien, berechnete Seiten und Anfragen) werden als spezielle Unterklassen angeboten. Um eine URL dem Server bekannt zu machen, muß sie dem Server explizit bekannt gemacht werden. Durch diesen Export von URL kann eine Kontrolle über die am Server verfügbaren Seiten ausgeübt werden.
Wenn eine HTML-Datei exportiert wird, erhält man das übliche Verhalten des Servers: Bei Aufruf der URL wird diese Datei eingelesen und übertragen. Daneben - und das stellt das eigentlich Interessante von CL-HTTP dar - gibt es Klassen von "berechneten" URLs. Wenn diese URL aufgerufen wird, wird eine bestimmte LISP-Funktion aufgerufen, die die Ausgabe berechnet. Das gleiche gilt für die Behandlung von Anfragen ("forms"), bei denen sowohl die Anfrageseite als auch die Antwortseite durch eine Funktion bestimmt werden. Durch diesen Mechanismus lassen sich einfach dynamisch Seiten erzeugen.
Damit man sich eine Vorstellung von der Vorgehensweise
machen kann, soll an dieser Stelle ein kurzes Beispiel gezeigt
werden, das dynamisch eine HTML-Seite ausgibt:
;Einfaches Beispiel einer dynamisch erzeugten HTML-Seite
;gibt Datum und Uhrzeit aus
(defun beispiel (url stream)
(multiple-value-bind ((year month day hour min sec) get-decoded-time ()
(format stream "<HTML><HEAD>Datumsanzeige</HEAD>")
(format stream "<BODY><TITLE>Datumsanzeige></TITLE>")
(format stream "<P>Heute ist der ~a. ~a. ~a. Es ist ~a:~a:~a Uhr." day month year hour min sec)
(format stream "</BODY></HTML>")
))
;Exportieren der Seite
(http:export-url #u"/beispiel.html" ;die URL
:html-computed ;"berechnete" Seite
:response-function #beispiel ;die Funktion, die aufgerufen wird
:expiration `(:time ,(* 15. 80.))
:keywords '(:cl-http)
:documentation "beispiel")
Da es auf die Dauer nicht sinnvoll ist, direkt auf
diese Weise HTML-Code zu erzeugen, wurde in dieser Arbeit ein
Texterzeugungswerkzeug benutzt, das während des Projektpraktikums
"Intelligente Informationssysteme" erstellt wurde. Dieses
erlaubt unter anderem die Verwendung von Textbausteinen, die den
HTML-Code erzeugen.
![]()
![]()
![]()
![]()
![]() 3.4.2. Die Klasse LinkAppleScript
3.4.2. Die Klasse LinkAppleScript
Durch die in Kapitel 3.3 Übersicht über die entwickelten Klassen vorgestellten Klassen wird es ermöglicht, APPLESCRIPT-fähige Applikationen an den Server anzubinden. Dabei wird für jede Anbindung eine Instanz einer Klasse angelegt. Es wäre wünschenswert, wenn effiziente und einfach bedienbare Mechanismen für die Verwaltung dieser Instanzen existieren.
Diese werden in der Klasse LinkAppleScript zur Verfügung gestellt. Für die Verwaltung der Anbindungen ist es wichtig, daß die Anbindungen zur Laufzeit des Servers geschaffen, geändert oder gelöscht werden können. Ebenso werden Methoden zum Laden und Speichern der Konfiguration benötigt, damit bei einem Neustart des Servers alle Anbindungen erhalten bleiben. Die Änderungen am System sollen über das WWW erfolgen, so daß es nicht erforderlich ist, daß der Systemverwalter direkt am Server tätig werden muß. Dabei ergibt sich das Problem, das überwacht werden muß, wer Änderungen durchführen darf, da jeder über das Netz den Server ansprechen kann.
Um dieses Problem zu lösen, wurde ein einfacher Passwortschutz eingebaut. Der Systemverwalter hebt einmal durch Eingabe eines Passwortes die Sperre auf, kann danach die Änderungen durchführen und die Sperre wieder setzen. Es soll dabei nicht verschwiegen werden, daß während der Zeit, in der die Sperre aufgehoben wurde, jeder beliebige diese Änderungen durchführen darf. Dieses Problem wurde aus dem Grund nicht beachtet, da das komplette System im Moment nur auf einen Benutzer ausgerichtet ist. Es ist zwar möglich, daß mehrere Benutzer gleichzeitig auf die gleiche Anbindung zugreifen können, dabei ist die Korrektheit der Operationen aber nicht mehr gesichert.
Das zugrundeliegende Problem liegt darin begründet, das HTTP ein zustandsloses Übertragungsprotokoll ist. Wenn mehrere Benutzer gleichzeitig auf einen Server zugreifen, kann dieser dadurch auch nicht in Verwirrungen oder Mehrdeutigkeiten gestürzt werden. Durch die Verwendung von Klassen in LISP, die intern an manchen Stellen Zustände, Ergebnisse, u.ä. speichern, geht die Zustandslosigkeit verloren. Eine Lösung dieses Problems könnte in der Richtung erfolgen, daß über HTTP ein zustandsgesteuertes Protokoll emuliert wird. Dies könnte darin bestehen, daß wenn zum ersten Mal eine Anbindung angesprochen wird, eine Kopie der Instanz angelegt wird, die beim "Verlassen" der Anbindung wieder vernichtet wird.
Für die Klasse LinkAppleScript wurden
außerdem HTML-Seiten zur Verfügung gestellt, über
die das Erzeugen, Löschen und Ändern von Anbindungen
durchgeführt werden kann. In diesen HTML-Seiten wurden vor
allem Hilfestellungen und Erklärungen für die Konfiguration
eingebaut. Nach einer Änderung werden die Änderungen
dem Server mitgeteilt. Wenn z.B. eine neue Anbindung geschaffen
wird, werden automatisch die für diese Anbindung vorhandenen
Standardseiten exportiert und auf einer Einstiegsseite zugänglich
gemacht.
Als Ergänzung zu der von CL-HTTP zur Verfügung gestellten Funktionalität wurde die Klasse Router implementiert. Diese umfasst nur wenige Methoden, weshalb auf diese Klasse nur sehr kurz eingegangen werden soll. Zum einen erlaubt es diese Klasse, die IP-Nummer des Clients zu speichern, was für das Loggen (s. nächstes Kapitel) für Bedeutung ist. Der zweite wesentliche Mechanismus, der durch diese Klasse bereitgestellt wird, ist eine Umsetzungstabelle von IP-Nummer und Rechnernamen für bestimmte Rechner. Zusätzlich kann für jeden Rechner dieser Tabelle ein Benutzername und ein dazugehöriges Passwort abgelegt werden. In diese Tabelle wurden in diesem Fall alle APPLE-Rechner des Lehrstuhls eingetragen. Dieses wird für das Ausführen von APPLESCRIPTS auf anderen Rechnern benötigt. Zusätzlich wird in dieser Klasse eine Tabelle zum Umsetzen von Rechnernamen und den an diese angeschlossenen Platten zur Verfügung gestellt. Dies wird u.a. zum Kopieren von Dumps benötigt.
Da sich die in diesen Tabellen enthaltenen Daten
ändern können (z.B. durch neue Rechner oder Festplatten),
lassen sich die Einträge auf einer HTML-Seite verändern.
Dadurch kann auf eine Umkonfiguration des lokalen Netzes auf einfache
Weise am Server eingegangen werden.
Da die vom Server angebotenen Dienste Ressourcen in Anspruch nehmen, ist es in manchen Fällen notwendig, dem Benutzer die Benutzung dieser Ressourcen in Rechnung zu stellen. Dazu benötigt man eine ausreichend genaue Übersicht über die vom Benutzer ausgelösten Aktionen. Zu diesem Zweck wurde während des Projektpraktikums "Intelligente Informationssysteme" von Claudia Settele ein Logbuch-System entwickelt. Damit lassen sich sowohl die Anzahl angeforderter Datensätze einer Datenbank (etwa beim Suchen) als auch Änderungen (z.B. bei der Konfiguration) festhalten.
Durch die Anzahl der vom Benutzer angeforderten Datensätze hat man eine Abschätzung, wieviel Ressourcen dessen Anfrage in Anspruch genommen hat. Dieses Maß ist für den Benutzer fair, da nur wirklich erhaltene Informationen in Rechnung gestellt werden können. Wenn man die benötigten Ressourcen z.B. am Zeitaufwand zur Bearbeitung der Anfrage festmachen würde, wäre dieses Maß von vielen vom Benutzer unabhängigen Faktoren bestimmt.
Durch das Mitloggen der Konfigurationsänderungen hat der Systemverwalter eine Übersicht über die Geschichte des Systems, die es ihm z.B. ermöglicht, einen Fehler schnell zu lokalisieren.
Da die Aktionen am Server über das WWW ausgelöst werden, kann allerdings nur die IP-Adresse des Benutzers erfahren werden, nicht aber direkt der Name des Benutzers.
![]()
![]()
![]()
![]()
![]()
In diesem Kapitel sollen alle Anbindungen, die im
Rahmen dieser Arbeit konkret realisiert wurden, vorgestellt werden.
Damit läßt sich ein Überblick gewinnen, für
welche Einsatzgebiete das entwickelte System geeignet erscheint.
Für einige Anbindungen wurden zusätzliche Funktionalität
in Form zusätzlicher oder geänderter HTML-Seiten zur
Verfügung gestellt, worauf jeweils gesondert eingegangen
werden soll.
![]()
![]()
![]()
![]()
![]() 3.5.1. Anbindungen an FILEMAKER
PRO
3.5.1. Anbindungen an FILEMAKER
PRO
Für die Anbindungen von FILEMAKER PRO an den HTTP-Server wurden mehrere Datenbanken verwendet, von denen zwei an dieser Stelle vorgstellt werden sollen. Für jede Datenbank wird dabei eine Instanz der Klasse FileMaker angelegt, die durch LinkAppleScript verwaltet wird.
WWW - Adressen
Als erste Datenbank mit für Benutzer
interessanten Daten wurde eine Datenbank mit Adressen im World
Wide Web benutzt. Diese Datenbank enthält zur
Zeit ungefähr 1000 Einträge.
Wenn man eine Suche nach einer gewünschten Adresse durchgeführt hat, so würde man im Normalfall die gefundenen Daten in einem ähnliche Format auf einer HTML-Seite erhalten. Da der Benutzer daran interessiert ist, eine der gefundenen Adressen auch anzuwählen, wurde die für das Anzeigen vorhandene Funktion überladen, wobei folgendes verwirklicht wurde:
Die erste Spalte Titel wurde beim Anzeigen
so abgeändert, daß nicht nur der Text dargeboten wird,
sondern zusammen mit der zweiten Spalte URL ein Verweis
(Link) auf diese Adresse. Damit kann der Benutzer sofort die von
ihm gewünschte Adresse anwählen. Zur Illustration eine
Antwort auf eine Suchanfrage, wobei eine Suchanfrage selbst aus
drei verknüpfbaren Einzelanfragen besteht, die aus Platzgründen
nicht auf einer Seite dargestellt werden können :

Bücherdatenbank des Lehrstuhls VI
Die zweite verwendete Datenbank stellt ein Verzeichnis von Büchern dar, die am Lehrstuhl VI der Informatik vorhanden sind. Dieses Verzeichnis ist (noch) nicht vollständig und enthält im Moment ca. 250 Buchtitel.
Auch hier wurde für die Anzeige neue Funktionalität
implementiert. Dabei sollte folgendes Szenario beachtet werden:
Da APPLESCRIPTS auch über ein Netzwerk auf anderen Rechnern ausgeführt werden können, bietet sich die Möglichkeit an, den einzufügenden Text über ein APPLESCRIPT dem Benutzer zu schicken. Damit dieser den Text empfangen werden kann, muß er eine "AppleScript-fähige" Textverarbeitung gestartet haben. Da im Rahmen dieser Arbeit nur WORD 6.0 behandelt wurde, funktioniert der Mechanismus nur mit dieser Applikation. Wenn das System durch andere skriptfähige Textverarbeitungen erweitert wird, läßt sich dieser Mechanismus einfach anpassen.
Dem Benutzer kann und soll allerdings die Entscheidung nicht abgenommen werden, an welcher Stelle und in welchem Format der Literaturverweis eingefügt werden soll. Daher wird der Text auch unformatiert an der aktuellen Position des im Vordergrund stehenden Dokumentes eingefügt.
Zwei Einschränkungen, die die Rechner, auf denen
dieser Mechanismus anwendbar ist, betreffen, müssen an dieser
Stelle vorgestellt werden:
Durch die Einfügeoperation erhält man eine Art von Client-Server-Kommunikation, die deshalb ungewöhnlich ist, da zwei verschiedene Protokolle - nämlich HTTP und APPLESCRIPT - für Hin- und Rücktransport der Daten benutzt werden, und da am Client zwei verschiedene Programme, nämlich der Browser und das Textverarbeitungsprogramm, die Informationen verschicken bzw. empfangen.
Zur Illustration folgt eine Suchanfrage und die darauf
erhaltene Antwort:
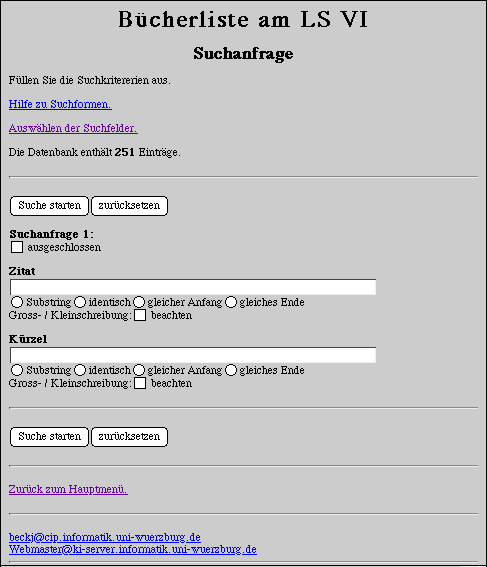
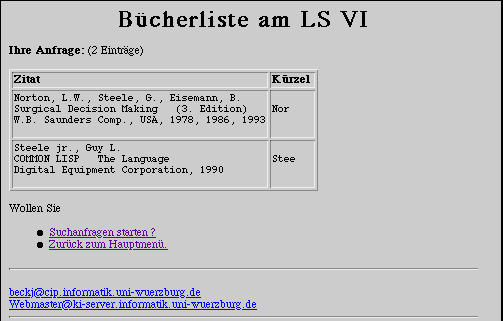
Wenn die Anfrage von einem der APPLE-Rechner des
Lehrstuhls gestartet wird, und auf diesem Rechner WORD läuft,
so lassen sich die Suchergebnisse in das aktuelle Dokument übernehmen.
Dabei erhält man folgenden Ablauf:
Die Sucheingabe bleibt identisch, als nächstes
fragt das System nach, ob es sich auf dem Rechner des Benutzers
einloggen darf. Da auf dem Rechner WORD läuft, bietet das
System an die Suchergebnisse einzufügen und fügt den
ausgewählten Eintrag in das Dokument ein.

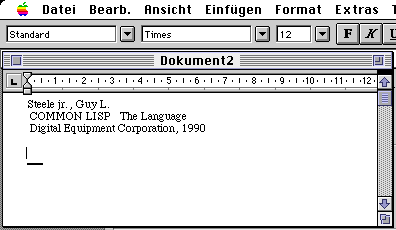
 |

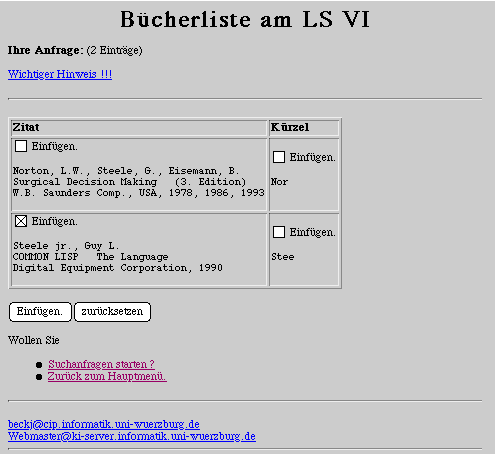 |
![]()
![]()
![]()
![]()
![]() 3.5.2. Anbindungen an MICROSOFT
WORD
3.5.2. Anbindungen an MICROSOFT
WORD
Bei der Auswahl eines sinnvollen Dokumentes für
eine Anbindung an WORD muß beachtet werden, daß beim
Anzeigen des Inhaltes auf einer HTML-Seite keine Formatierungen
des Dokumentes berücksichtigt werden können, es sei
denn, es wird vorher eine Konvertierung von WORD-Dokumenten in
HTML durchgeführt. Daher sollte für diese Anwendung
auf Dokumente verzichtet werden, die diese Eigenschaften besitzen,
da dadurch nur ein größerer Rechenaufwand entsteht.
Es erscheint daher auch nicht sinnvoll, diesen Mechanismus zum
kompletten Durchlesen dieser Dokumente zu benutzen, da dies wegen
der fehlenden Formatierungen sehr anstrengend wäre. Angebracht
erscheint es hingegen, mit dieser Anbindung Texte auf Stichworte
zu durchsuchen, und nur die betreffenden Absätze zu lesen.
Als Beispiele, welche Textdokumente generell sinnvoll erscheinen,
können folgende Beispiele genannt werden:
Als konkretes Beispiel wurde ein Dokument gewählt,
das gebräuchliche technische Abkürzungen der Informatik
enthält. Das Dokument enthält ca. 2000 Abkürzungen,
von denen als Beispiel die ersten fünf Einträge dargestellt
werden soll, damit ein Überblick über die Struktur des
Dokumentes entsteht:
A Ampere A/UX Apple UniX AA Auto Answer Add Accelerator AACE Association for the Advancement of Computing in Education AARP AppleTalk Address Resolution Protocol
Bei der Suche nach Stichwörtern, wird in diesem
Fall immer die Zeile, in der sich der gefundene Ausdruck befindet
präsentiert. Größere Textfragmente pro Stichwort
anzuzeigen, ist in diesem Fall nicht sinnvoll. Abschließend
noch eine Suchanfrage für WORD-Dokumente:

Als Beispiele, für welche Zwecke APPLE´S
FINDER genutzt werden kann, wurden zwei verschiedene Anwendungen
implementiert, die aber in ihrer Grundstruktur ähnlich sind.
Da diese Anbindungen nicht im Vordergrund der Studienarbeit standen,
wurde in diesen beiden Fällen eine Lösung erarbeitet,
die zeigt,daß solche Anbindungen realisierbar sind und wie
man dabei vorgehen kann. Ein erheblicher Teil der Funktionalität,
die für diese beiden Anwendungen entwickelt wurde, wird für
das Erstellen und Verteilen von Dumps benutzt, so daß diese
beiden Anwendungen eher als Vorstufe zu letzterem, denn als ausgereifte
Systeme zu verstehen sind.
Ausführen von APPLESCRIPTS
Für diese Anwendung wird ein Wurzelverzeichnis festgelegt, innerhalb dessen Unterverzeichnisse sich der Benutzer durch Auswahl des nächsten Verzeichnisses bewegen kann. Der Benutzer kann auch eine Datei, die sich im aktuellen Verzeichnis befindet, auswählen. Diese Datei wird auf dem Server ausgeführt. Dazu muß im Prinzip diese Datei kein ausführbares Programm sein. Wenn die Datei ein Dokument ist, dann wurde sie mit irgendeiner Applikation erstellt, und es wird diese Applikation gestartet und die Datei geladen.
Als geeignete Programme für dieser Anwendung bieten sich z.B. APPLESCRIPTS an.
Mini FTP
Es wird analog zu oben ein Wurzelverzeichnis
festgelegt, innerhalb dessen man sich durch die Verzeichnisse
bewegen kann. Wenn eine Datei ausgewählt wird, wird diese
auf den Client kopiert. Zusätzlich wurden noch Funktionen
implementiert, wie sie ein Dateimananger bietet. Wenn der Benutzer
die entsprechende Berechtigung besitzt, kann er jede Datei innerhalb
des vereinbarten Baumes löschen, kopieren, umbenennen oder
duplizieren. Dies sind ungefähr die Funktionen, die ein berechtigter
Benutzer auf einem FTP-Server ausführen darf. Da beide Anwendungen
eine recht ähnliche Darstellung besitzen, soll nur von einer
ein Beispiel gezeigt werden:

![]()
![]()
![]()
![]()
![]() 3.5.4. Erstellen und Verteilen
von LISP-Dumps
3.5.4. Erstellen und Verteilen
von LISP-Dumps
Für die Dumpentwicklung wurden zwei konkrete Anwendungen realisiert, nämlich das Erstellen der "Bibliothek 2.0.1", die aus der Grundversion von MCL 2.0 erstellt wird, und die XPS-Shell "D3", das als Grundbibliothek die eben erwähnte "Bibliothek 2.0.1" benutzt. Eine dritte und vierte Anwendung, nämlich das Erstellen der Bibliothek und von D3 auf Grundlage von MCL 3 ist geplant. Für beide Anwendungen wurden ähnliche HTML-Seiten entwickelt, so daß abwechselnd von beiden Beispiele gezeigt werden.
Bibliothek 2.0.1
Bibliothek 2.0.1 ist das ausgefertigte Beispiel für
die Klasse BibBuilder. Die Eigenschaften dieser Klasse
wurden bereits in Abschnitt 3.3.5 Die Klassen ASDumpManager, D3Builder und BibBuilder
beschrieben. Mit dieser Anwendung läßt sich die LISP-Bibliothek 2.0.1 erstellen. Fertige
Bibliotheken können von der Archivplatte auf einzelne Rechner
kopiert werden, was hier gezeigt werden soll:

D3
Die Anwendung der Klasse D3Builder wurde zum
Erstellen und Verteilen der XPS-Shell D3 implementiert. Da die
Funktionen der Klasse bereits in Abschnitt 3.3.5 Die Klassen ASDumpManager, D3Builder und BibBuilder beschrieben worden sind,
sollen an dieser Stelle nur Beispiele für die Benutzung dieser
Klasse und der zu dieser Klasse gehörenden HTML-Seiten
gezeigt werden.
Als Einstieg für die Benutzung wird die folgende
Seite angeboten, mit der auch die für Bibliothek 2.0.1 vorhandenen
Seiten angewählt werden können (diese sind nur aus Platzgründen
nicht zu sehen).

Wenn ein Dump gebaut werden soll (ohne daß
dafür Default-Werte benutzt werden), erhält der Anwender
folgende Seite, in der Optionen festgelegt werden können:

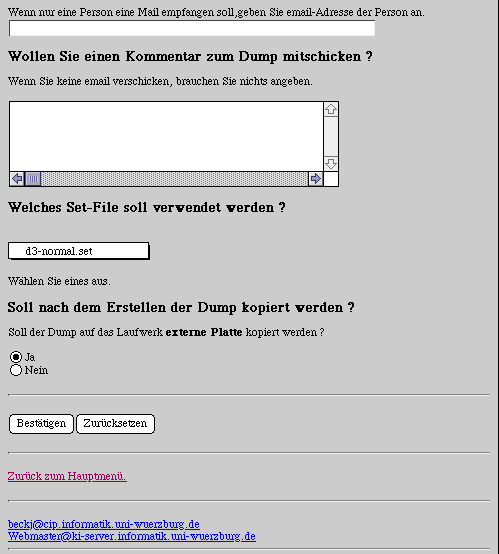
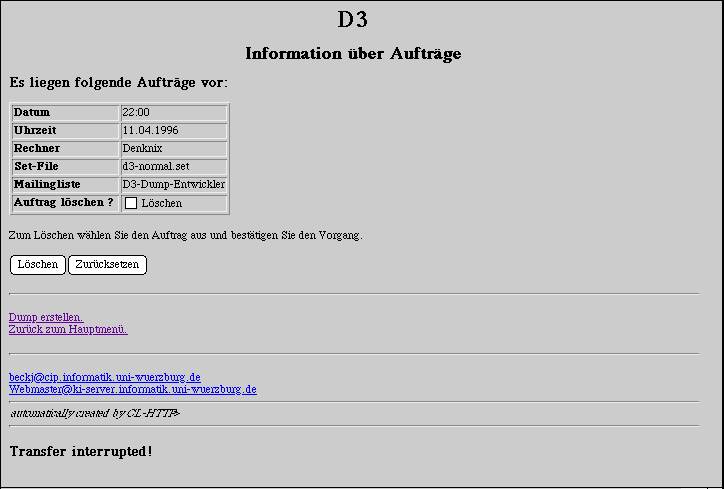
Wenn ein Dump gebaut werden soll, wird der Auftrag
in eine Warteschlange aufgenommen, aus der der Auftrag zur gewünschten
Zeit geholt wird, um ihn auszuführen. Das abschließende
Beispiel zeigt die Informationen über die vorliegenden Aufträge
an:
![]()
![]()
![]()
![]()
![]()
4. Hard- und
Softwareanforderungen
Für den Server wird folgende Hardwareausstattung
empfohlen:
Folgende Software wird unbedingt benötigt. In
Klammern ist der jeweilige Bedarf an Haupt- und Festplattenspeicher
angegeben (Erfahrungswerte):
Die folgenden Programme können unter Verzicht
auf bestimmte Eigenschaften des Systems weggelassen werden:
Für den Client wird die Benutzung des Browsers
NETSCAPE NAVIGATOR 2.0 (oder neuer) empfohlen.
![]()
![]()
![]()
![]()
![]()
Die Quelltexte der in dieser Studienarbeit entwickelten
Programme können vom Lehrstuhl VI bezogen werden. Aufgrund
ihres Umfanges und der zusätzlich verwendeten Tools ist ein
Abdruck nicht sinnvoll.
| [Beh95] |
Hennig Behme: Im Kaffeehaus; HotJava: objektorientierte Programmiersprache und Web-Viewer, iX 7/95, S. 120 ff |
| [Min96] |
Stefan Mintert: JavaScript: neue Netscape-Möglichkeiten; Annäherungsversuch, iX 2/96, S. 134 ff |
| [W3C96] |
World Wide Web Consortium W3C, http://www.w3.org/pub/WWW/CGI/ |
| [ScG96] |
Oliver Schmelzle, Christian Gast: Datenbankanwendungen mit dem W3-Gateway für mSQL; Angebunden, iX 2/96, S. 158 ff |
| [And95] |
Frank-Uwe Andersen; Sparprogramm; mSQL - Shareware-Datenbanksystem für kleine Ansprüche, iX 11/95, S. 88 |
| [Ber95] |
Klaus Bergner, Wolfgang Bartsch, Peter Braun, Sascha Molterer, Günter Teubner: TIS - Einbindung relationaler Datenbanken ins Web; Pflegeleicht, iX 11/95, S. 172 ff |
| [Per95] |
Louis Perrochon, Roman Fischer: IDLE: Unified W3-access to interactive information servers, Computer Networks and ISDN Systems 27 (1995), S. 927-938 |
| [Ncs95] |
National Center for Supercomputer Applications NCSA, http://hoohoo.ncsa.uiuc.edu/ |
| [Sch94] |
Derrick Schneider (Hans Hansen, Tim Holmes): The Tao of AppleScript / 2nd Edition, Hayden Books, BMUG, IN, 1994 |
| [Wor92] |
Woltersmann, Frank: Der Workshop zu Microsoft WordBasic, Microsoft Press Deutschland, 1994 |
| [Wol96] | Michael Wolber: Entwicklung einer generischen Architektur für die Benutzerschnittstelle von verteilten Systemen, Diplomarbeit im Fach Informatik, Universität Würzburg, S.37-42 |
| [Oec96] |
Oechslein, Christoph: (noch nicht veröffentlicht), Studienarbeit im Fach Informatik, Universität Würzburg |
| [Jav95] |
JavaScript Sprachreferenz, http://userver.informatik.uni-wuerzburg.de/HTMLs/jsdoc/index.html |
| [Clh96] |
Documentation of CL-HTTP, Massachusetts Institute of Technology, Artificial Intelligence Laboratory, http://www.ai.mit.edu/projects/iiip/doc/cl-http/home-page.html |